매개변수 갱신
- 신경망 학습의 목적은 손실 함수의 값을 가능한 한 낮추는 매개변수를 찾는 것
- 이것은 매개변수의 최적값을 찾는 문제이며, 이러한 문제를 푸는 것을 최적화라 함.
확률적 경사 하강법(SGD)

class SGD:
def __init__(self, lr = 0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]- optimizer는 '최적화를 행하는 자'라는 뜻
- 매개변수 갱신은 optimizer가 책임지고 수행하니 optimizer에 매개변수와 기울기 정보만 넘겨주면 됨.
SGD의 단점
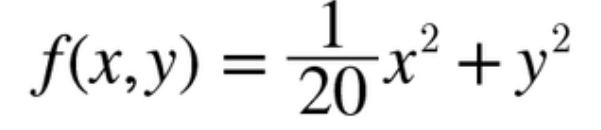
함수의 그래프와 등고선
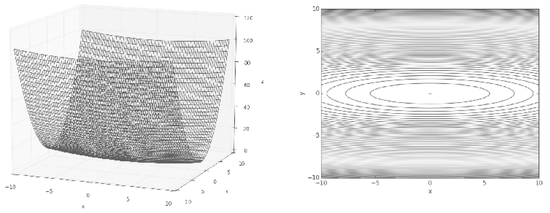
[SGD에 의한 최적화 갱신 경로: 최솟값인 (0,0)까지 재그재그로 이동하니 비효율적이다.
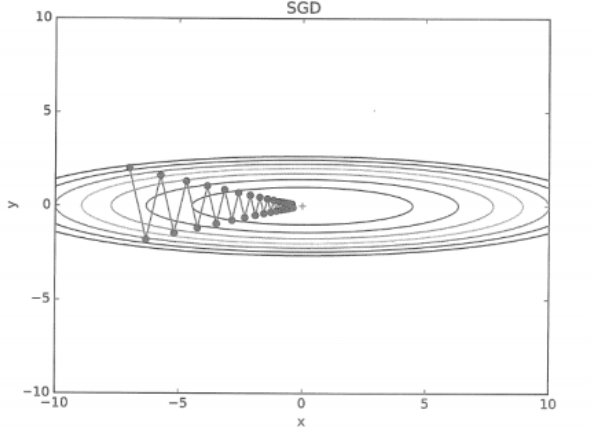
- SGD의 단점은 비등방성 함수(방향에 따라 성질, 기울기가 달라지는 함수)에서는 탐색 경로가 비효율적임.
- SGD의 단점을 개선해주는 방법: 모멘텀, AdaGrad, Adam
모멘텀(Momentum)
- 모멘텀은 운동량을 뜻하는 단어로, 물리와 관계가 있음.
- 모멘텀 수식은 다음과 같이 쓸 수 있음.
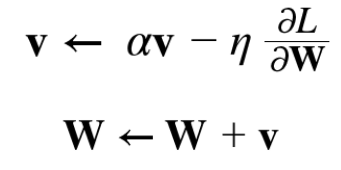
- W는 갱신할 가중치 매개변수, 손실함수에 대한 기울기, η는 학습률임. v는 물리에서 말하는 속도에 해당됨.
- 모멘텀은 공이 그릇의 바닥을 구르는 듯한 움직임을 보여줌.
- αv항은 물체가 아무런 힘을 받지 않을 때 서서히 하강시키는 역할. 물리에서의 지면 마찰이나 공기 저항에 해당
# 모멘텀 구현
import numpy as np
class Momentum:
def __init__(self, lr = 0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key][모멘텀에 의한 최적화 갱신 경로]

- 모멘텀의 갱신 경로는 공이 그릇 바닥을 구르듯 움직임.
- SGD와 비교하면 '지그재그 정도'가 덜함. 이는 x축의 힘은 아주 작지만 방향은 변하지 않아서 한 방향으로 일정하게 가속하기 때문임.
- 거꾸로 y축의 힘은 크지만 위아래로 번갈아 받아서 상충하여 y축 방향의 속도는 안정적이지 않음.
- 전체적으로 SGD보다 x축 방향으로 빠르게 다가가 지그재그 움직임이 줄어듦.
AdaGrad
- 신경망 학습에는 학습률 값이 중요함. 이 값이 너무 작으면 학습 시간이 너무 길어지고, 반대로 너무 크면 발산하여 학습이 제대로 이루어지지 않음.
- 이 학습률을 정하는 효과적 기술로 학습을 진행하면서 학습률을 점차 줄여가는 학습률 감소가 있음.
- 이를 더욱 발전시킨 것이 AdaGrad임. AdaGrad는 '각각의 매개변수에 맞는 맞춤형' 값을 만들어줌.
- AdaGrad는 개별 매개변수에 적응적으로 학습률을 조정하면서 학습을 진행함.
- AdaGrad의 갱신 방법 수식
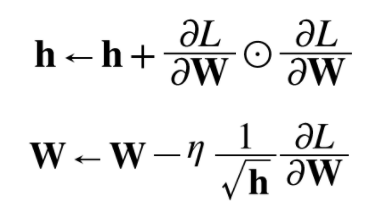
- AdaGrad는 과거의 기울기를 제곱하여 계속 더해감. 그래서 학습을 진행할수록 갱신 강도가 약해짐. 실제로 무한히 계속 학습한다면 어느 순간 갱신량이 0이 되어 전혀 갱신되지 않게 됨. 이 문제를 개선한 기법으로 RMSProp이라는 방법이 있음. RMSProp은 과거의 모든 기울기를 균일하게 더해가는 것이 아니라, 먼 과거의 기울기는 서서히 잊고 새로운 기울기 정보를 크게 반영함. 이를 지수이동평균이라 하여, 과거 기울기의 반영 규모를 기하급수적으로 감소시킴.
# AdaGrad 구현
class AdaGrad:
def __init__(self, lr = 0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)- 여기에서 주의할 것은 마지막 줄에서 1e-7이라는 작은 값을 더하는 부분임. 이 작은 값은 self.h[key]에 0이 담겨있다 해도 0으로 나누는 사태를 막아줌.
[AdaGrad]에 의한 최적화 갱신 경로

그림을 보면 최솟값을 향해 효율적으로 움직임. y축 방향은 기울기가 커서 처음에는 크게 움직이지만, 큰 움직임에 비례해 갱신 정도도 큰 폭으로 작아지도록 조정됨. 그래서 y축 방향으로 갱신 강도가 빠르게 약해지고, 지그재그 움직임이 줄어듦.
Adam
- 모멘텀은 공이 그릇 바닥을 구르는 듯한 움직임을 보이고, AdaGrad는 매개변수의 원소마다 적응적으로 갱신 정도를 조정함. 이 두 기법을 융합한 것이 Adam임.
- 매개변수 공간을 효율적으로 탐색해주고, 하이퍼파리머트의 '편향 보정'이 진행됨.
[Adam에 의한 최적화 갱신 경로]

- Adam 갱신 과정도 그릇 바닥을 구르듯 움직임. 모멘텀과 비슷한 패턴인데, 모멘텀 때보다 공의 좌우 흔들림이 적음. 이는 학습의 갱신 강도를 적응적으로 조정해서 얻는 혜택임.
Optimizer 비교
# optimizer 비교
import sys, os
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
from common_optimizer import *
def f(x, y):
return x**2 / 20.0 + y**2
def df(x, y):
return x / 10.0, 2.0*y
init_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0
optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=0.95)
optimizers["Momentum"] = Momentum(lr=0.1)
optimizers["AdaGrad"] = AdaGrad(lr=1.5)
optimizers["Adam"] = Adam(lr=0.3)
idx = 1
for key in optimizers:
optimizer = optimizers[key]
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(30):
x_history.append(params['x'])
y_history.append(params['y'])
grads['x'], grads['y'] = df(params['x'], params['y'])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# for simple contour line
mask = Z > 7
Z[mask] = 0
# plot
plt.subplot(2, 2, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="red")
plt.contour(X, Y, Z)
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
#colorbar()
#spring()
plt.title(key)
plt.xlabel("x")
plt.ylabel("y")
plt.show()
# mnist 데이터셋으로 optimizer 비교
import os
import sys
sys.path.append(os.pardir)
import matplotlib.pyplot as plt
from mnist import load_mnist
from common_util import smooth_curve
from common_multi_layer_net import MultiLayerNet
from common_optimizer import *
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000
optimizers = {}
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
#optimizers['RMSprop'] = RMSprop()
networks = {}
train_loss = {}
for key in optimizers.keys():
networks[key] = MultiLayerNet(
input_size=784, hidden_size_list=[100, 100, 100, 100],
output_size=10)
train_loss[key] = []
for i in range(max_iterations):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for key in optimizers.keys():
grads = networks[key].gradient(x_batch, t_batch)
optimizers[key].update(networks[key].params, grads)
loss = networks[key].loss(x_batch, t_batch)
train_loss[key].append(loss)
if i % 100 == 0:
print( "===========" + "iteration:" + str(i) + "===========")
for key in optimizers.keys():
loss = networks[key].loss(x_batch, t_batch)
print(key + ":" + str(loss))
markers = {"SGD": "o", "Momentum": "x", "AdaGrad": "s", "Adam": "D"}
x = np.arange(max_iterations)
for key in optimizers.keys():
plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 1)
plt.legend()
plt.show()
- 참고: 밑바닥부터 시작하는 딥러닝1
- notobook ipynb file: https://github.com/heejvely/Deep_learning/blob/main/%EB%B0%91%EB%B0%94%EB%8B%A5%EB%B6%80%ED%84%B0_%EC%8B%9C%EC%9E%91%ED%95%98%EB%8A%94_%EB%94%A5%EB%9F%AC%EB%8B%9D_1/%ED%95%99%EC%8A%B5%20%EA%B4%80%EB%A0%A8%20%EA%B8%B0%EC%88%A0%EB%93%A4.ipynb
GitHub - heejvely/Deep_learning: deep learning 기초 공부
deep learning 기초 공부. Contribute to heejvely/Deep_learning development by creating an account on GitHub.
github.com
'Deep Learning' 카테고리의 다른 글
| [Deep Learning]배치 정규화(Batch Normalization) (0) | 2022.11.13 |
|---|---|
| [Deep Learning] 가중치의 초깃값 (0) | 2022.11.13 |
| [Deep Learning]오차역전파의 계산법 (0) | 2022.11.11 |
| [Deep Learning]최소제곱법 (0) | 2022.11.10 |
| [Deep Learning] 오차역전파법 구현(Back Propagation) (0) | 2022.11.07 |