바른 학습을 위해
기계 학습에서는 오버피팅이 문제가 되는 일이 많음. 오버피팅이란 신경망이 훈련 데이터에만 지나치게 적응되어 그 외의 데이터에는 제대로 대응되지 못하는 상태를 말함.
오버피팅은 주로 다음의 두 경우에 일어남.
1. 매개변수가 많고 표현력이 높은 모델
2. 훈련 데이터가 적음
# 오버피팅 결과
import os
import sys
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from mnist import load_mnist
from common_multi_layer_net import MultiLayerNet
from common_optimizer import SGD
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 오버피팅을 재현하기 위해 학습 데이터 수를 줄임
x_train = x_train[:300]
t_train = t_train[:300]
max_epochs = 201
train_size = x_train.shape[0]
batch_size = 100
weight_decay_lambda = 0.1
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10, weight_decay_lambda=weight_decay_lambda)
optimizer = SGD(lr = 0.01)
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grads = network.gradient(x_batch, t_batch)
optimizer.update(network.params, grads)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs)
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
가중치 감소
오버피팅 억제용으로 예로부터 많이 이용해온 방법 중 가중치감소가 있음. 이는 학습 과정에서 큰 가중치에 대해서는 그에 상응하는 큰 패널티를 부과하여 오버피팅을 억제하는 방법임. 원래 오버피팅은 가중치 매개변수의 값이 커서 발생하는 경우가 많기 때문
# λ = 0.1로 가중치 감소를 적용한 결과
import os
import sys
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from mnist import load_mnist
from common_multi_layer_net import MultiLayerNet
from common_optimizer import SGD
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 오버피팅을 재현하기 위해 학습 데이터 수를 줄임
x_train = x_train[:300]
t_train = t_train[:300]
weight_decay_lambda = 0.1
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10, weight_decay_lambda=weight_decay_lambda)
optimizer = SGD(lr = 0.01)
max_epochs = 201
train_size = x_train.shape[0]
batch_size = 100
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grads = network.gradient(x_batch, t_batch)
optimizer.update(network.params, grads)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(f'epoch {epoch_cnt}, train_acc: {train_acc}, test_acc: {test_acc}')
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs)
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
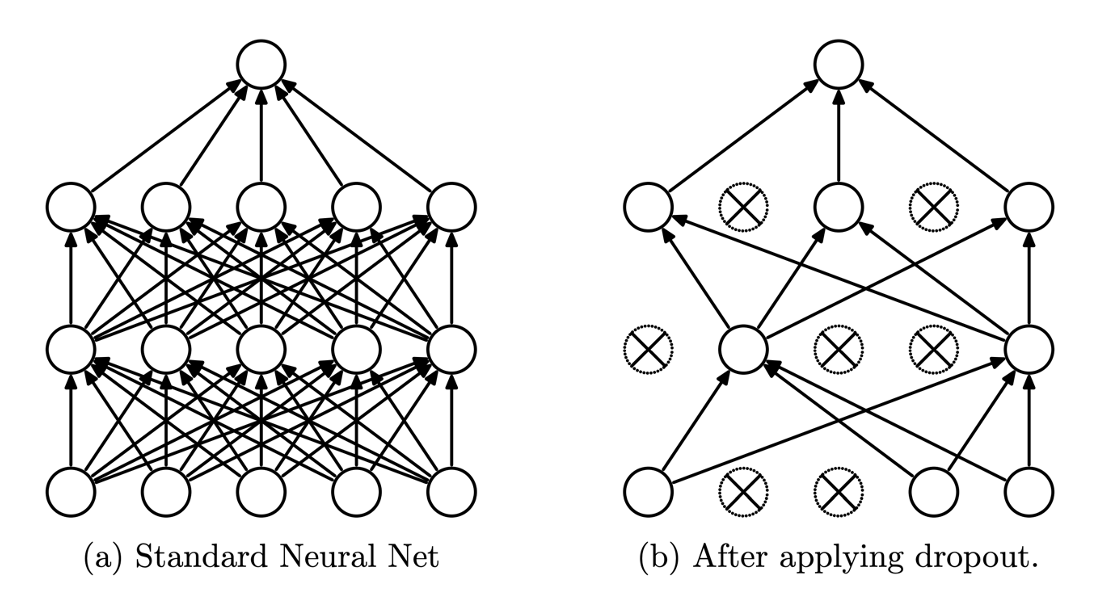
드롭아웃(Dropout)
- 신경망 모델이 복잡해지면 오버피팅의 억제를 드롭아웃 기법을 이용함.
- 드롭아웃은 뉴런을 임의로 삭제하면서 학습하는 방법임. 훈련 때 은닉층의 뉴런을 무작위로 골라 삭제하고, 삭제된 뉴런은 신호를 전달하지 않게됨.
- 훈련 때는 데이터를 흘릴 때마다 삭제한 뉴런을 무작위로 선택하고, 시험 때는 모든 뉴런에 신호를 전달함. 단, 시험 때는 각 뉴런의 출력에 훈련 때 삭제 안 한 비율을 곱하여 출력함.
[드롭아웃의 개념: 왼쪽이 일반적인 신경망, 오른쪽이 드롭아웃을 적용한 신경망, 드롭아웃은 뉴런을 무작위로 선택해 삭제하며 신호 전달을 차단한다.]
# 드롭아웃 구현
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ration = dropout_ratio
self.mask = None
def forward(self, x, train_flg = True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask- 삭제할 뉴런을 False로 표시함.
- self.mask는 x와 형상이 같은 배열을 무작위로 생성하고, 그 값이 dropout_ratio보다 큰 원소만 True로 설정함.
- 역전파 때와 동작은 ReLU와 같음. 즉, 순전파 때 신호를 통과시키는 뉴런은 역전파 때도 신호를 그대로 통과시키고, 순전파 때 통과시키지 않은 뉴런은 역전파 때도 신호를 차단함.
# 드롭아웃 적용 안할 시 오버피팅
import os
import sys
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from mnist import load_mnist
from common_multi_layer_net_extend import MultiLayerNetExtend
from common_trainer import Trainer
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
x_train = x_train[:300]
t_train = t_train[:300]
use_dropout = True
dropout_ratio = 0
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],
output_size=10, use_dropout=use_dropout, dropout_ration=dropout_ratio)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=301, mini_batch_size=100,
optimizer='sgd', optimizer_param={'lr': 0.01}, verbose=True)
trainer.train()
train_acc_list, test_acc_list = trainer.train_acc_list, trainer.test_acc_list
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()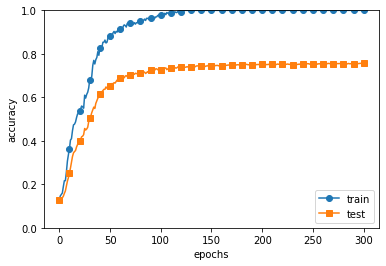
# 드롭아웃 적용
import os
import sys
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from mnist import load_mnist
from common_multi_layer_net_extend import MultiLayerNetExtend
from common_trainer import Trainer
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
x_train = x_train[:300]
t_train = t_train[:300]
use_dropout = True
dropout_ratio = 0.2
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],
output_size=10, use_dropout=use_dropout, dropout_ration=dropout_ratio)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=301, mini_batch_size=100,
optimizer='sgd', optimizer_param={'lr': 0.01}, verbose=True)
trainer.train()
train_acc_list, test_acc_list = trainer.train_acc_list, trainer.test_acc_list
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()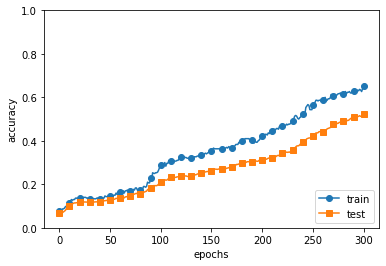
- 드롭아웃 적용 후 훈련데이터와 시험 데이터에 대한 정확도 차이가 줄어듦.
- 훈련 데이터에 대한 정확도가 100%에 도달하지도 않게 됨.
적절한 하이퍼파라미터 값 찾기
검증 데이터
훈련 데이터는 매개변수(가중치와 편향)의 학습에 이용하고, 검증 데이터는 하이퍼파라미터의 성능을 평가하는 데 이용함. 시험 데이터는 범용 성능을 확인하기 위해서 마지막에 (이상적으로는 한 번만) 이용함.
- 훈련 데이터: 매개변수 학습
- 검증 데이터: 하이퍼파라미터 성능 평가
- 시험 데이터: 신경망의 범용 성능 평가
# 검증데이터 얻는 방법: 훈련 데이터 중 20%를 검증 데이터로 분리
from mnist import load_mnist
from common_util import shuffle_dataset
(x_train, t_train), (x_test, t_test) = load_mnist()
# 훈련 데이터를 뒤섞는다.
x_train, t_train = shuffle_dataset(x_train, t_train)
# 20%를 검증 데이터로 분할
validation_rate = 0.2
validation_num = int(x_train.shape[0] * validation_rate)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]하이퍼파라미터 최적화
- 하이퍼파라미터를 최적화할 때의 핵심은 하이퍼파라미터의 '최적 값'이 존재하는 범위를 조금씩 줄여간다는 것
- 범위를 조금씩 줄이려면 우선 대략적인 범위를 설정하고, 그 범위에서 무작위로 하이퍼파라미터 값을 골라낸(샘플링) 후, 그 값으로 정확도를 평가함.
- 정확도를 잘 살피면서 이 작업을 여러번 반복하여 하이퍼파리미터의 '최적 값'의 범위를 좁혀가는 것임.
- 신경망의 하이퍼파라미터 최적화에서는 그리드 서치같은 규칙적인 탐색보다는 무작위로 샘플링해 탐색하는 편이 좋은 결과를 낸다고 알려져있음. 이는 최종 정확도에 미치는 영향력이 하이퍼파라미터마다 다르기 때문임.
- 하이퍼파라미터의 범위는 대략적으로 지정하는 것이 효과적임. 실제로도 0.001에서 1.000 사이와 같이 10의 거듭제곱 단위로 범위를 지정함. 이를 로그 스케일로 지정한다고 함.
- 0단계
- 하이퍼 파라미터 값의 범위를 설정합니다.
- 1단계
- 설정된 범위에서 하이퍼파라미터의 값을 무작위로 추출합니다.
- 2단계
- 1단계에서 샘플링한 하이퍼파라미터 값을 사용하여 학습하고, 검증 데이터로 정확도를 평가합니다.(단, 에폭은 작게 설정합니다.)
- 3단계
- 1단계와 2단계를 특정 횟수(100회 등) 반복하며, 그 정확도의 결과를 보고 하이퍼파라미터의 범위를 좁힙니다.
하이퍼파라미터 최적화 구현하기
# mnist를 이용한 하이퍼 파라미터 최적화 구현
import sys, os
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from mnist import load_mnist
from common_multi_layer_net import MultiLayerNet
from common_util import shuffle_dataset
from common_trainer import Trainer
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
x_train = x_train[:500]
t_train = t_train[:500]
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_train, t_train = shuffle_dataset(x_train, t_train)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]
def __train(lr, weight_decay, epocs=50):
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],
output_size=10, weight_decay_lambda=weight_decay)
trainer = Trainer(network, x_train, t_train, x_val, t_val,
epochs=epocs, mini_batch_size=100,
optimizer='sgd', optimizer_param={'lr': lr}, verbose=False)
trainer.train()
return trainer.test_acc_list, trainer.train_acc_list
optimization_trial = 100
results_val = {}
results_train = {}
for _ in range(optimization_trial):
weight_decay = 10 ** np.random.uniform(-8, -4)
lr = 10 ** np.random.uniform(-6, -2)
val_acc_list, train_acc_list = __train(lr, weight_decay)
print("val acc:" + str(val_acc_list[-1]) + " | lr:" + str(lr) + ", weight decay:" + str(weight_decay))
key = "lr:" + str(lr) + ", weight decay:" + str(weight_decay)
results_val[key] = val_acc_list
results_train[key] = train_acc_list
print("=========== Hyper-Parameter Optimization Result ===========")
graph_draw_num = 20
col_num = 5
row_num = int(np.ceil(graph_draw_num / col_num))
i = 0
for key, val_acc_list in sorted(results_val.items(), key=lambda x:x[1][-1], reverse=True):
print("Best-" + str(i+1) + "(val acc:" + str(val_acc_list[-1]) + ") | " + key)
plt.subplot(row_num, col_num, i+1)
plt.title("Best-" + str(i+1))
plt.ylim(0.0, 1.0)
if i % 5: plt.yticks([])
plt.xticks([])
x = np.arange(len(val_acc_list))
plt.plot(x, val_acc_list)
plt.plot(x, results_train[key], "--")
i += 1
if i >= graph_draw_num:
break
plt.show()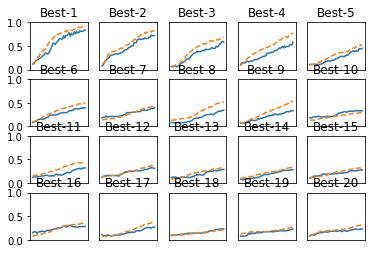
- 참고: 밑바닥부터 시작하는 딥러닝1
- notobook ipynb file: https://github.com/heejvely/Deep_learning/blob/main/%EB%B0%91%EB%B0%94%EB%8B%A5%EB%B6%80%ED%84%B0_%EC%8B%9C%EC%9E%91%ED%95%98%EB%8A%94_%EB%94%A5%EB%9F%AC%EB%8B%9D_1/%ED%95%99%EC%8A%B5%20%EA%B4%80%EB%A0%A8%20%EA%B8%B0%EC%88%A0%EB%93%A4.ipynb
GitHub - heejvely/Deep_learning: deep learning 기초 공부
deep learning 기초 공부. Contribute to heejvely/Deep_learning development by creating an account on GitHub.
github.com
'Deep Learning' 카테고리의 다른 글
| [Deep Learning] 오차 수정하기: 경사하강법, 편미분 코드 구현 (0) | 2022.11.22 |
|---|---|
| [Deep Learning]퍼셉트론(Perceptron) (0) | 2022.11.16 |
| [Deep Learning]배치 정규화(Batch Normalization) (0) | 2022.11.13 |
| [Deep Learning] 가중치의 초깃값 (0) | 2022.11.13 |
| [Deep Learning]Optimizer 매개변수 갱신 (2) | 2022.11.13 |